Introduction
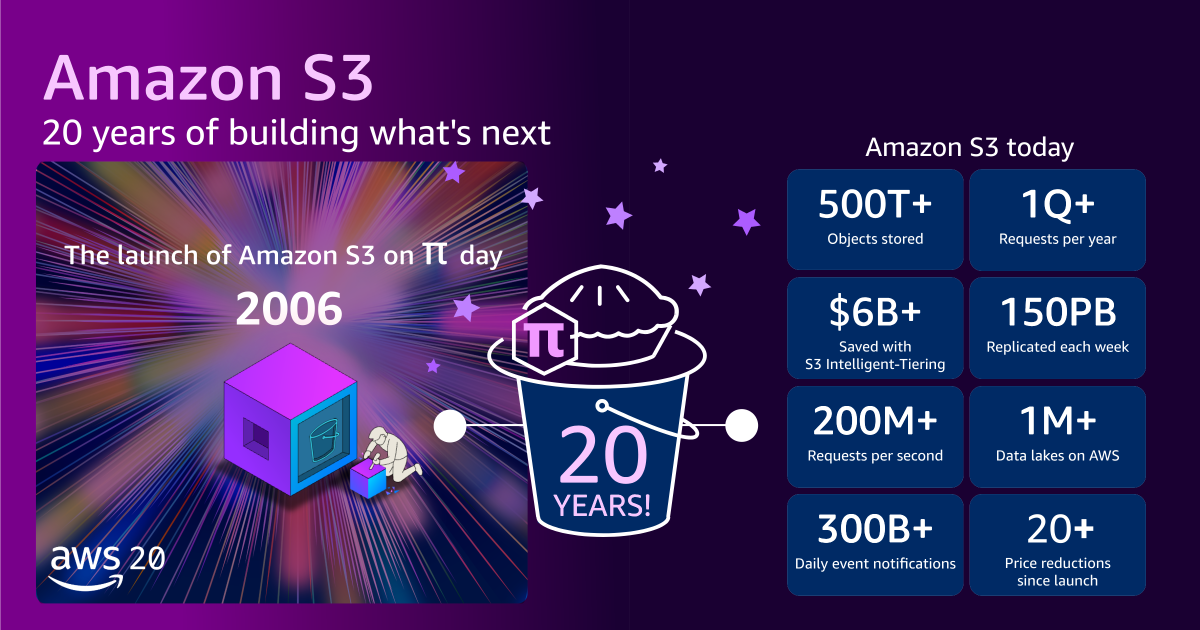
Twenty years ago, on March 14, 2006, Amazon S3 launched with a quiet announcement. Today, it stores over 500 trillion objects and serves 200 million requests per second. This guide doesn't just recount history—it translates Amazon S3's core principles into actionable steps you can use to build your own scalable, durable, and cost-effective storage system. Whether you're a developer starting a new project or an architect modernizing legacy infrastructure, the lessons from S3's two decades of evolution apply directly to your work.
What You Need
- An AWS account (or equivalent cloud provider) with permissions to create S3 buckets
- Basic understanding of cloud storage concepts (objects, buckets, regions)
- Access to AWS documentation and pricing pages
- Optional: a sample application that stores user-generated content to test your design
Step-by-Step Guide
Step 1: Embrace the Simple PUT/GET Paradigm
Amazon S3 succeeded by keeping the interface dead simple. Your storage system should start with two core operations: PUT to store an object and GET to retrieve it later. Avoid overcomplicating the API with custom methods unless absolutely necessary. This minimalism makes the system predictable and easy to integrate. For example, in your application, use HTTP requests to a RESTful endpoint—just like S3's original design. Doing this from day one lets you focus on higher-level business logic rather than managing storage internals.
Step 2: Implement Security by Default
Security was a founding principle of S3: your data is protected by default. In your design, enforce encryption at rest and in transit from the start. Use bucket policies and IAM roles to deny all access unless explicitly permitted. Follow the least-privilege model—grant only the permissions required for each user or application. Regularly audit access logs. By baking security into the architecture, you eliminate the risk of accidental exposure and build trust with your users.
Step 3: Design for 11 Nines of Durability
S3 famously achieves 99.999999999% durability—meaning objects are virtually lossless. To replicate this, your system must store multiple copies of every object across geographically separate locations. Use erasure coding or replication strategies that survive simultaneous failures (e.g., one entire data center down). Automate data integrity checks with regular checksum verification and repair processes. While your implementation may not need exactly 11 nines, targeting at least 99.999999% ensures your customers never lose data.
Step 4: Plan for High Availability at Every Layer
Availability in S3 is designed into every layer, assuming that failure is always present. Build your storage with multiple, independent failure domains—at least three Availability Zones if using AWS, or equivalent redundancy on other platforms. Your system should survive the loss of a single zone without impact. Use load balancers and auto-scaling groups for compute resources. Test failure scenarios regularly (e.g., Chaos Engineering) to validate that your fallback mechanisms work.
Step 5: Optimize Performance Without Degradation
From its first petabyte of capacity to hundreds of exabytes today, S3 maintains consistent performance. To achieve this, your storage architecture must support concurrent access from millions of clients. Use distributed file systems or object stores that scale horizontally. Avoid single points of contention such as a centralized metadata server. Implement caching layers for frequently accessed data. Monitor latency metrics and adjust partitioning schemes as data grows. Remember: performance is not just speed but also predictability under load.
Step 6: Ensure Automatic Elasticity
S3 grows and shrinks automatically as you add or remove data—no manual intervention. Your system should do the same. Use cloud-native services that provision storage capacity on demand. Set up auto-scaling policies that add nodes when usage exceeds thresholds and remove them when idle. This elasticity not only handles unpredictable spikes (e.g., viral content) but also reduces cost by avoiding overprovisioning. Test your scaling limits by simulating sudden bursts of uploads or deletions.

Step 7: Plan for Cost Reduction Over Time
S3's price dropped from 15¢ per GB in 2006 to roughly 2¢ per GB today—a 7x reduction. While you may not control pricing of underlying hardware, you can design your system to become cheaper as it grows. Use tiered storage classes (like S3 Intelligent-Tiering or Glacier) to move cold data to lower-cost media. Negotiate volume discounts with your cloud provider. Optimize data compression and deduplication. Build a cost-monitoring dashboard and set budgets that automatically right-size resources. Remember: a scalable storage system should also scale in cost efficiency.
Tips for Long-Term Success
- Start small, think big. Launch with a single bucket and a few users, but architect for the millions of requests S3 handles today. Use modular components so you can swap out storage backends later.
- Automate everything. From backup to scaling to cost optimization, manual operations don't scale. Write infrastructure-as-code (e.g., Terraform, CloudFormation) to make your design repeatable.
- Learn from S3's journey. The five fundamentals—security, durability, availability, performance, elasticity—are timeless. Even if you don't need all five on day one, build them in incrementally. Your future self will thank you.
- Test for the impossible. S3 assumes failure is always present. Simulate hard drive crashes, network partitions, or a full region outage. Your recovery plan shouldn't be theoretical; it should be proven.
- Monitor, measure, improve. Use detailed logging and metrics (e.g., CloudWatch, Datadog) to track object counts, request latency, error rates, and costs. Set alerts for anomalies. Continuously iterate on your design based on real-world data.
- Embrace the simplicity. The most elegant storage systems are those that developers barely notice. Keep your APIs simple, your documentation clear, and your operations invisible. That's the secret behind S3's enduring success.
By following these steps, you'll create a storage foundation that can scale from a few terabytes to hundreds of exabytes, just as S3 did over 20 years. The technology may evolve, but the principles remain: simplicity, resilience, and cost-effectiveness are the building blocks of lasting cloud storage.